container native networking

Networking with containers and Kubernetes is an important piece and plays a critical role on a security, performance and reliability standpoints (pod-to-pod communications as well as communications in and out a Kubernetes cluster). With this article, I would like to list 4 main networking features GCP is providing for your GKE clusters. Again, those are important concepts to leverage but that’s also the opportunity to demonstrate how Google is innovating, contributing and leading in such areas.
- VPC-native cluster
- Default for your GKE clusters very soon if not already.
- Container-native Load Balancing
- Default for your GKE clusters very soon if not already.
- GKE Dataplane V2
- Interesting future for GKE clusters with eBPF via Cilium.
- Service Mesh
- Beyond the buzz, that’s an important piece when scaling your containerized (but not only) workloads.
VPC-native cluster
Since its announcement in October 2018, VPC-native clusters for GKE is the default cluster network mode when you create a GKE cluster from within the Google Console but not yet via REST API nor the Google Cloud SDK/CLI. VPC-native clusters use alias IP ranges for pod networking. This means that the control plane automatically manages the routing configuration for pods instead of configuring and maintaining static routes for each node in the GKE cluster. I have found these following resources very valuable to understand why we should use this VPC-native clusters mode for better capabilities around security, performance and integration with other GCP services:
- VPC-native clusters compared to routes-based clusters
- The ins and outs of networking in Google Container Engine and Kubernetes (Google Cloud Next ‘17)
- VPC-native clusters on Google Kubernetes Engine
So here is now how I will create my GKE cluster to leverage this feature (FYI you can’t update an existing cluster to get this feature):
gcloud container clusters create \
--enable-ip-alias
VPC-native clusters tend to consume more IP addresses in the network, so you should take that into account. This guide Understanding IP address management in GKE explains really well what you should know about Pod range, Service range, subnet range, etc.
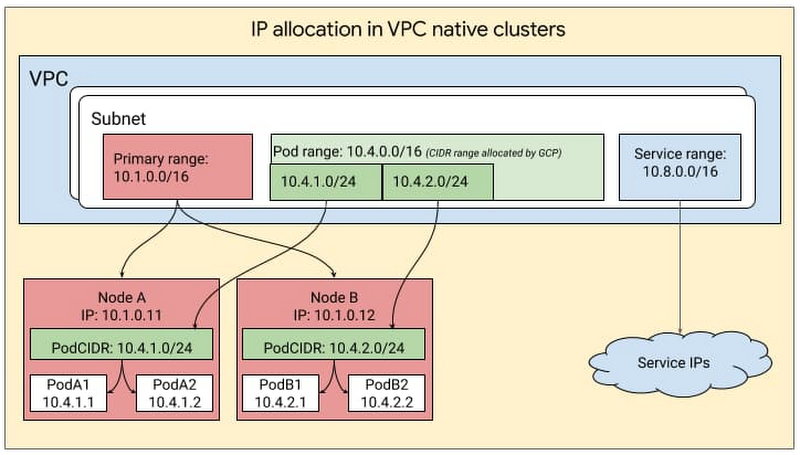
Based on this, the example below is provisioning a cluster with auto-mode IP address management + limiting the IP addresses consumption for both nodes/pods and services:
gcloud container clusters create \
--enable-ip-alias \
--max-pods-per-node 30 # instead of 110 \
--default-max-pods-per-node 30 # instead of 110 \
--services-ipv4-cidr '/25' # instead of /20 \
--cluster-ipv4-cidr '/20' # instead of /14
Container-native Load Balancing
Once you have deployed a containerized app in Kubernetes, you have many ways to expose it through a Service or an Ingress: NodePort Service, ClusterIP Service, Internal LoadBalancer Service, External LoadBalancer Service, Internal Ingress, External Ingress or Multi-cluster Ingress. This following resource will walk you through all those concepts: GKE best practices: Exposing GKE applications through Ingress and Services. To expose an Ingress on GKE I have found this following resource very valuable as well: Ingress features which provides a comprehensive list of supported features for Ingress on GCP.
Since October 2018, GCP has introduced a container-native load balancing on GKE.
Without container-native load balancing, load balancer traffic travels to the node instance groups and gets routed via iptables rules to Pods which might or might not be in the same node. With container-native load balancing, load balancer traffic is distributed directly to the Pods which should receive the traffic, eliminating the extra network hop. Container-native load balancing also helps with improved health checking since it targets Pods directly.

For this you need to provision your GKE cluster with the --enable-ip-aliases parameter and then add the cloud.google.com/neg: '{"ingress": true}' annotation on your Service (even if you expose it via an Ingress). The recommendation is to explicitly set this annotation where you need it, even if in some cases it will be applied by default under certain conditions. You could also find the associated requirements, restrictions and limitations information about that feature. You could then see the associated network endpoint groups generated by running this command: gcloud compute network-endpoint-groups list.
Other features and services you could now leverage in addition to the load balancer is Cloud Armor (WAF), Identity-Aware Proxy (IAP) or Cloud CDN for example. Here is how to Configure Ingress features through BackendConfig parameters.
It’s also important to note that the Google Cloud Load Balancing is Global (not regional) with single anycast IP (not DNS-based) and it’s managed software-defined service (not instance- or device-based solution). The Chapter 11 of the SRE Workbook describes Google’s approach to traffic management with its GCLB.
Cloud Load Balancing is built on the same frontend-serving infrastructure that powers YouTube, Maps, Gmail, Search, etc. It supports 1 million+ queries per second with consistent high performance and low latency. Traffic enters Cloud Load Balancing through 80+ distinct global load balancing locations, maximizing the distance traveled on Google’s fast private network backbone.
GKE Dataplane V2
The New GKE Dataplane V2 (leveraging eBPF via Cilium) which increases security and visibility for containers has just been announced recently.
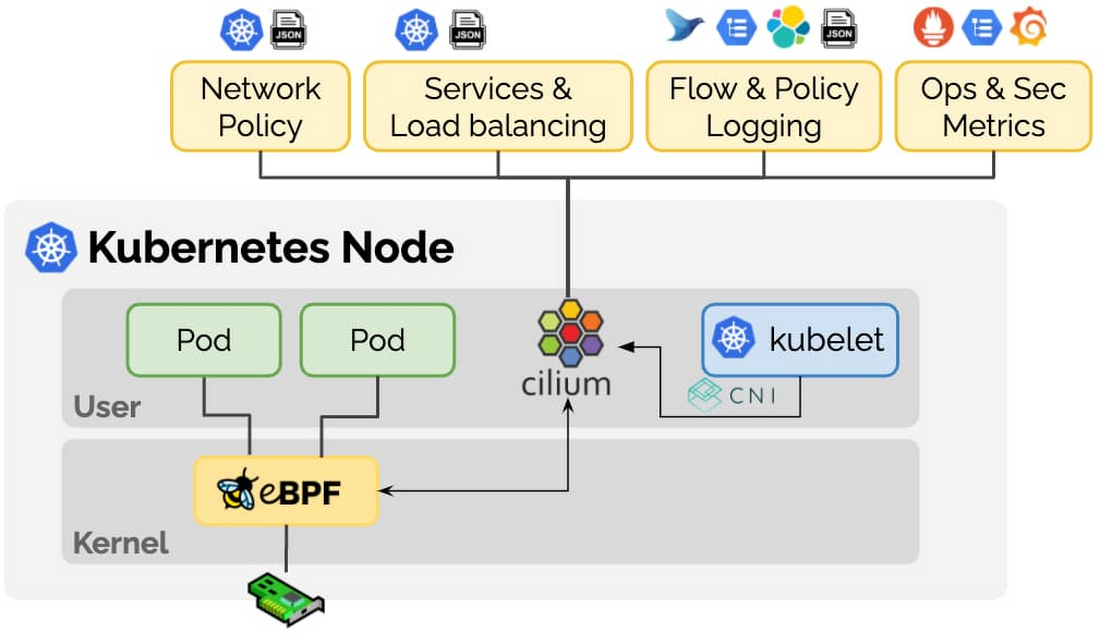
eBPF is a revolutionary technology that can run sandboxed programs in the Linux kernel without recompiling the kernel or loading kernel modules. Over the last few years, eBPF has become the standard way to address problems that previously relied on kernel changes or kernel modules. In addition, eBPF has resulted in the development of a completely new generation of tooling in areas such as networking, security, and application profiling.
Cilium is an open source project that has been designed on top of eBPF to address the new scalability, security and visibility requirements of container workloads. Cilium goes beyond a traditional Container Networking Interface (CNI) to provide service resolution, policy enforcement and much more.
On Cilium’s blog article for the announcement, you could also read the story behind that partnership between Cilium, Google and actually the broad open source community, I love that!
Google clearly has incredible technical chops and could have just built their dataplane directly on eBPF, instead, the GKE team has decided to leverage Cilium and contribute back. This is of course a huge honor for everybody who has contributed to Cilium over the years and shows Google’s commitment to open collaboration.
This feature is in beta as we speak, but seems really promising! Like described in this tutorial you could give it a try by provisioning a new cluster with this command gcloud beta container clusters create --enable-dataplane-v2. From there, you will be able for example to leverage new features like network policy logging.
Service Mesh
When talking about networking with containers and Kubernetes, we can’t avoid the Service Mesh area. If you are not familiar with Service Mesh or you are wondering why you do (or don’t) need a Service Mesh for your own context, I highly encourage you to watch this session Building Globally Scalable Services with Istio and ASM] which is explaining really well what a Service Mesh is.
Istio
Istio is one of the Service Mesh out there, you could deploy it on any Kubernetes cluster; with this configuration you need to manage the setup, the update, as well as dealing with the fact that Istio and its components are sharing the same resources of your worloads within your cluster. This article Welcome to the service mesh era: Introducing a new Istio blog post series provides more information about Istio and its components and features. There is also this tutorial walking you through Extending your Istio service mesh across GKE clusters and Compute Engine instances.

Anthos Service Mesh (ASM)
Another step now is, what if you would like a managed Istio service? Here comes Anthos Service Mesh (ASM)! For this you need an Anthos subscription. This tutorial From edge to mesh: Exposing service mesh applications through GKE Ingress will walk you through the setup of either ASM or Istio on your GKE cluster, very convenient to see the differences. ASM supports 3 main profiles: asm-gcp (on GKE), asm-gcp-multiproject (GKEs on multi-projects) and asm-multicloud (GKE on-prem, GKE on AWS, attached EKS and attached AKS), and depending on the profile you need to check out which features are supported or not. And here is the guide to upgrade ASM on GKE, to give you an idea about this process.
Here are few resources to help you navigate throughout the capabilities and features of ASM:
- Ingress for Anthos
- Anthos Service Mesh Deep Dive
- Ingress for Anthos - Multi-cluster Ingress and Global Service Load Balancing
Traffic Director
The ultimate step is, what if you would like a managed Service Mesh’s Control Plane? Here comes Traffic Director!
In a service mesh, your application code doesn’t need to know about your networking configuration. Instead, your applications communicate over a data plane, which is configured by a control plane that handles service networking. Traffic Director is your control plane and the Envoy sidecar proxies are your data plane.
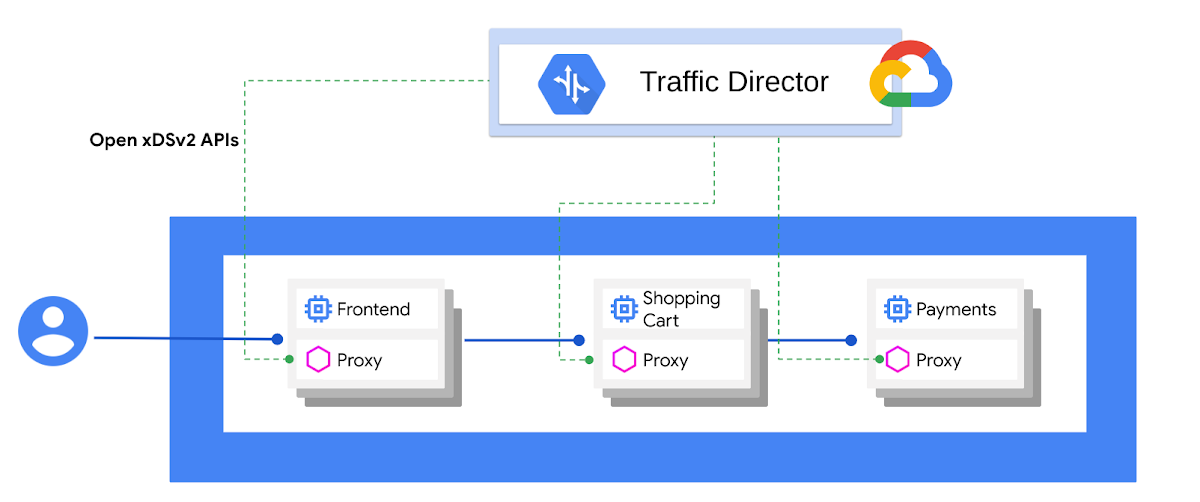
I went through this session Build an Enterprise-Grade Service Mesh with Traffic Director [Youtube] which is giving a great overview of what Traffic Director is. Even if here is a list of limitations you have to be aware of, I think this service is really promising. I don’t have to manage anymore Istio, this Istio control plane is outside my GKE cluster and I have the ability to get endpoints from different GKE clusters or GCEs. More features are coming for sure, recently for example two new ones got my attention: GKE Pods with automatic Envoy injection and Traffic Director and gRPC—proxyless services for your service mesh.
Here are few resources to help you navigate throughout the capabilities and features of Traffic Director:
- Traffic Director & Envoy-Based L7 ILB for Production-Grade Service Mesh & Istio (Cloud Next ‘19)
- How Traffic Director provides global load balancing for open service mesh
- Traffic Director — What is it and how is it related to the Istio service-mesh?
That’s a wrap! Hope you enjoyed this blog article and hopefully you will be able to leverage such impressive services and features for your own needs and context ;)
Complementary and further resources:
- How we’re advancing intelligent automation in network security
- Best practices for GKE networking
- Cloud Load Balancing Deep Dive and Best Practices (Cloud Next ‘18)
- GKE Networking Differentiators (Cloud Next ‘19)
- Scalable and Manageable: A Deep-Dive Into GKE Networking Best Practices (Cloud Next ‘19)
- What’s new in network security on Google Cloud (Cloud Next ‘20)
- Open systems: Key to Unlocking Multi-Cloud with Lyft, Juniper, Google (Cloud Next ‘19)
- Ready? A Deep Dive into Pod Readiness Gates for Service Health Management
Cheers! ;)